


Dans les médias, sans doute du fait des importants progrès réalisés au cours des dernières années grâce à ces techniques, l’Intelligence Artificielle est très souvent associée au Machine Learning et à sa branche la plus récente le Deep Learning. Pourtant, comme en témoigne sa définition formelle, l’IA correspond à un ensemble de techniques bien plus larges, dont le Machine Learning fait effectivement partie.
Concevoir un système d’Intelligence Artificielle revient en fait à combiner entre elles ces différentes techniques afin d’obtenir un système capable de réaliser une ou plusieurs des trois grandes tâches que composent le processus de décision humain, à savoir : Percevoir, Comprendre et Décider.
D’un point de vue informatique, “Percevoir” correspond à la collecte et au stockage de la donnée. “Comprendre” implique de structurer l’information à partir de cette donnée pour la rendre intelligible. Enfin, “Décider” correspond à l’exploitation de cette information de façon à trouver la meilleure réponse possible à un problème donné.
Dans cet article, nous verrons quelles techniques sont utilisées à chacune de ces étapes dans la conception de solutions basées sur l’IA.
Collecter et stocker : le rôle essentiel de l’IoT et du Big Data
La tâche de perception consiste à faire qu’une machine collecte (par ex via les technos IoT) et stocke de la donnée, dans un format utilisable pour des applications futures (i.e. toutes les technos de stockage). Pour les spécialistes, ce n’est pas à proprement parler “de l’IA”, car il n’y a pas de tâche à haute valeur ajoutée ici. Néanmoins, on peut l’inclure dans une définition de l’IA pensée comme un système complexe composé d’une multitude de techniques, et ce pour trois raisons :
- le fait que ce soit des tâches simples aujourd’hui ne veut pas dire que cela a toujours été le cas, ceux qui ont pratiqué la BI dans les années 90-2000 pourront vous le dire. La démocratisation des technologies de collecte et de stockage est récente et ne doit pas faire oublier les problématiques techniques sous-jacentes, parfois très complexes
- chez un être humain, on associe volontiers la mémoire à son intelligence. “Avoir bonne mémoire” c’est à la fois être capable d’absorber beaucoup d’information et la retenir. C’est exactement ce que font les technologies de collecte et de stockage de la donnée. Du point de vue des tâches à plus haute valeur ajoutée, elles semblent purement utilitaires, mais elles sont en réalité indispensables
- c’est aussi le moyen de rappeler l’importance de la qualité de la donnée et du fameux adage “garbage in, garbage out”. Si ce sont bien les étapes de compréhension et de décision qui génèrent de la valeur, c’est souvent la mauvaise qualité ou l’insuffisance de la data qui font échouer les projet d’IA

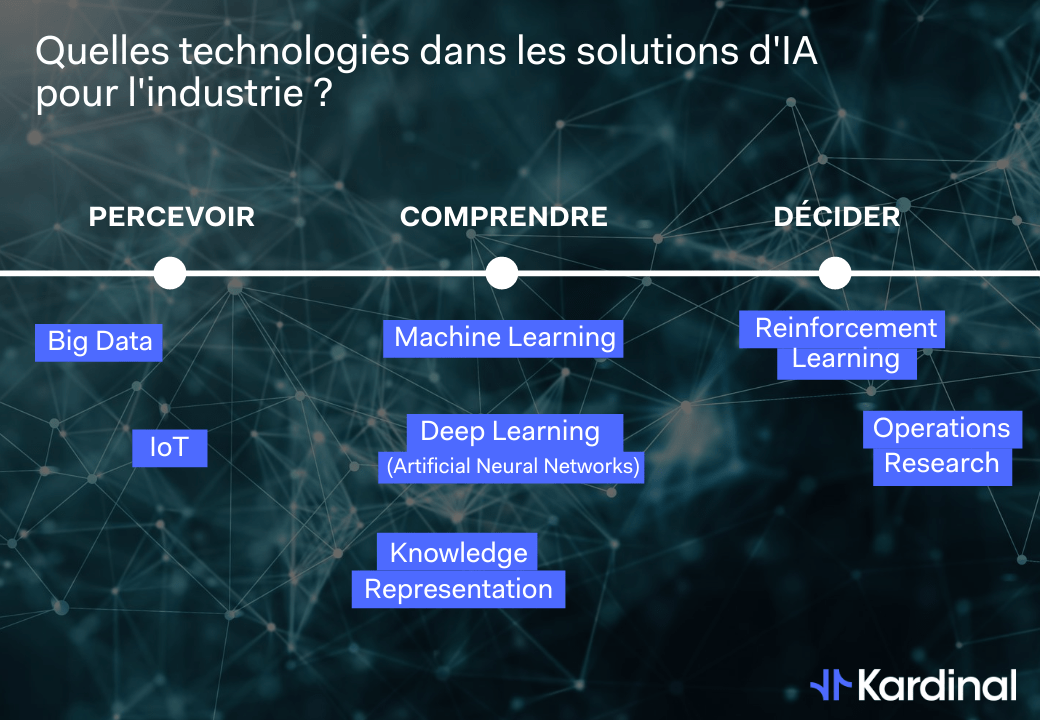
Trouver les pépites dans la donnée via le Machine Learning
Les deux tâches suivantes, la compréhension et la décision, sont souvent mélangées. On les distingue mal car certaines technologies font un peu les deux en même temps (l’apprentissage par renforcement et le deep learning utilisent tous les deux les réseaux de neurones, par exemple).
La compréhension revient à travailler la donnée pour la rendre intelligible, généralement via des analyses statistiques plus ou moins poussées. A ce titre, le Machine Learning est une forme avancée de statistiques qui va globalement consister à identifier des liens forts entre les données et tenter d’apporter des réponses à des questions qu’on peut se poser : qu’est-ce qui explique les pics de consommation d’un produit en particulier ? Quels sont les lieux où il est plus difficile ou plus long de livrer un colis ? Cette information n’existe pas à l’état brut dans les données collectées, et le but des algorithmes de Machine Learning est d’identifier ces liens de façon plus ou moins supervisée, pour pouvoir prédire ces données dans le futur. Récemment, on a vu le Deep Learning permettre des avancées impressionnantes dans des domaines où la machine était résolument en difficulté, comme la reconnaissance d’image (où les modèles vont reconnaître des entités dans des photographies ou des vidéos) ou le traitement du langage naturel (qui permet de déduire le sens d’une phrase à partir de son analyse). Ce sont surtout ces applications qui ont fait émerger le terme IA auprès du grand public car on y voit des machines réaliser des tâches qu’on pensait réalisables efficacement par l’Homme uniquement.
Les tâches de compréhension permettent donc d’extraire une information de haut niveau à partir de la donnée collectée, mais parfois, elles ne permettent pas de prendre une décision. Toutes les applications d’IA ne requièrent pas cette étape, mais il est malheureusement courant d’observer des projet d’IA en industrie où cette étape est particulièrement délaissée car mal identifiée. Par exemple, sur le dernier kilomètre, on peut prédire (avec du Machine Learning) l’évolution future du nombre de colis qu’une agence aura à traiter. On peut également imaginer que ce même modèle de ML puisse donner les décisions d’achat de tournées optimales auprès de leur prestataires : ce n’est absolument pas le cas. Le modèle va simplement évaluer la quantité future de colis, sous certaines hypothèses, et c’est tout. La décision optimale est plus complexe à obtenir et le ML n’est pas du tout la technique à retenir pour faire cela.
L’Aide à la Décision : le défi de la Recherche Opérationnelle et de l’Apprentissage par Renforcement
C’est donc le but des technologies d’aide à la décision, qui sont souvent méconnues. La plus ancienne, la Recherche Opérationnelle, traite des problématiques d’optimisation que l’on retrouve dans toutes les industries : optimisation d’investissements financiers, optimisation de la planification d’une usine, optimisation des tournées de livraison. Elle requiert une forte expertise mathématique et algorithmique et c’est généralement dans ces applications que l’IA peut véritablement faire “mieux” que l’homme, car elle s’attaque à des problèmes avec une très forte complexité. La RO permet et requiert qu’on lui décrive exactement (i.e. qu’on modélise) la problématique, pour que les algorithmes d’optimisation puissent explorer l’ensemble de solutions possibles à ce problème et trouver la meilleure. Cette capacité à “raisonner sous contrainte” est la grande force de cette approche qui permet aux algorithmes de gérer simultanément l’ensemble des contraintes métier de l’industrie. C’est aussi ce qui permet à ces algorithmes de trouver des solutions complètement “out of the box” même pour un oeil expert.
Cette force de la RO est aussi sa faiblesse. En effet, il faut décrire le problème, le modéliser, sous une forme mathématique de “choix possibles évalués”. Par exemple, sur une problématique d’optimisation de tournées, on peut décrire les tournées comme des suites de points qu’on évalue avec les kilomètres parcourus par l’ensemble des tournées. Or ce n’est pas toujours possible, comme pour certains jeux tels que les échecs, le Go ou encore les jeux vidéo (voir les succès récents d’OpenAI à Dota ou Starcraft). Ici, c’est l’évaluation d’une décision qui particulièrement difficile ! Comment évaluer “mathématiquement” un coup au Go ou un “clic” dans Starcraft ? Les combinaisons sont trop nombreuses et le modèle d’optimisation sous-jacent au problème, s’il existe, est sans doute inconnaissable. C’est sur ces problèmes que l’apprentissage par renforcement entre en jeu : s’il n’est pas possible d’expliquer à la machine quelle décision est la meilleure, apprenons lui à la trouver par elle-même. Ces techniques se basent sur la répétition à grande échelle, rendue possible par le cloud computing, du problème qui est soumis à la machine, inlassablement, afin qu’elle trouve ses propres stratégies par une alternance d’essais et d’erreur.
En définitive, concevoir un système d’IA, c’est donc agencer des technologies parfois très différentes, tant au niveau des techniques mathématiques qu’elles impliquent qu’au niveau de leur maturité. Il est très important de ne pas négliger la base : bien collecter et bien stocker. Il est également très important de positionner chaque technique au bon endroit : ne pas optimiser des décisions avec du Machine Learning, ne pas se lancer dans de l’apprentissage par renforcement sur un problème déjà bien résolu avec la Recherche Opérationnelle.
The Author


Cédric Hervet est docteur en Mathématiques Appliquées et co-fondateur de Kardinal. Depuis plus de 10 ans, il étudie et conçoit des systèmes d’Intelligence Artificielle pour des applications industrielles dans les secteurs des télécommunications, du marketing digital et du transport.
Sa double compétence en statistiques/Machine Learning ainsi qu’en algorithmie/Recherche Opérationnelle lui permet d’articuler ces deux grands ensembles de techniques pour concevoir les systèmes intelligents de demain.
Vous voulez en apprendre davantage ? Retrouvez les autres articles de notre dossier “Collaboration Humain-IA dans les solutions industrielles”


Introduction à l’Intelligence Artificielle pour l’Industrie : 3 questions à Cédric Hervet
Cédric Hervet est docteur en Mathématiques Appliquées et co-fondateur de Kardinal. Depuis plus de 10 ans, il étudie et conçoit des

Classification de la capacité à prendre des décisions : Machine versus Humain
On l’a vu, l’IA recouvre un ensemble de tâches et de techniques très variées. Néanmoins, d’un point de vue industriel,


Quelle place pour l’Humain dans les solutions d’IA pour l’industrie ?
La conception d’un système d’IA en industrie doit, pour qu’il ait du sens, apporter une valeur ajoutée, qu’elle soit qualitative